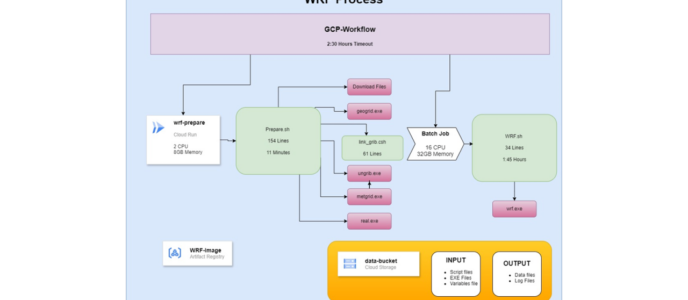
לפני כשבועיים שיתפתי בלינקדאין כיצד יעלתי הליך WRF.
התהליך שעבד בצורה מיושנת, נבנה מחדש על מנת לייעל אותו, להקל את העריכה שלו והפיקוח עליו, ולחסוך משמעותית בעלויות.
תהליך היעול שהתבצע בקצרה:
כל מערך הסקריפטים שמנה כ-5,000 שורות קוד, נבנה מחדש בשני סקריפטים (bash) של 230 שורות בסה"כ.
במקום ה-Container Image הישן ששקל מעל 4GB נבנה קונטיינר חדש ששוקל 240MB
במקום לרוץ על שרת שהוא VM שפועל 24.7, התהליך פועל באמצעות GCP Workflow. התהליך פועל כשעתיים. בתחילה התהליך מפעיל Cloud Run Job חסכוני במשאבים. ובחלק השני פועל Batch Job עם מכונה גדולה יותר.
בסוף התהליך משאבי המחשוב נעלמים עד לריצה הבאה.
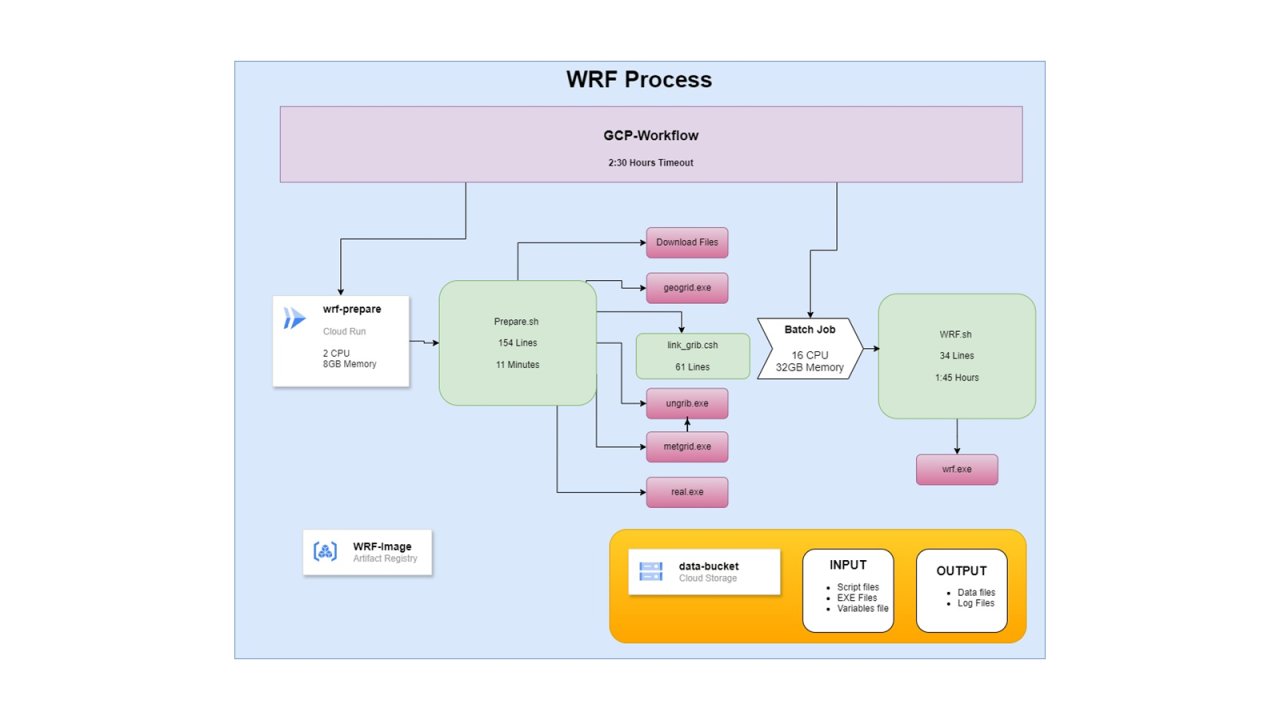
על הפרק:
במאמר הזה אני רוצה להדגים כיצד נוכל לקחת תהליך בן כמה שלבים, ולנהל אותו באמצעות GCP Workflow.
Workflow מהווה הליך לוגי שבו מגדירים שלבים, ובכל שלב פעולה שונה.
השלבים יכולים לכלול הרצה/הפעלה של רכיב, יצירת קריאת HTTP, בדיקת תנאי, לולאות וכו.
את התהליך מגדירים באמצעות YAML שבו כותבים את השלבים.
לפני שנכתוב את השלבים ב-Workflow, נרצה לראות שהם פועלים כמו שצריך בנפרד, בפני עצמם. ואז נראה איך לקרוא להם מתוך Workflow.
Artifact Registry:
רכיב זה כבר נזכר במאמרים קודמים שלי, ומהווה ספריית ענן עבור Images. לכן לא נתעכב עליו ונציין נתיב בדיוני של Container Image כאילו הוא יושב בו. אז נשתמש באותו Container Image לצורך הפעולות שנבצע.
Cloud Run Job:
במאמרים קודים הסברתי בפירוט כיצד להקים שירות (Service) על Cloud Run. שם גם צוין כי ההבדל בין משימה לבין שירות (Job, Service בהתאמה).
- שירות ממתין כל הזמן לקבל פניות.
- משימה רצה כשקוראים לה, מבצעת את מה שהיא צריכה לבצע, ואז היא מסתיימת.
אז לא נתעכב על Cloud Run. רק נזכור שלפני שנקרא למשימה מתוך Workflow, נרצה להגדיר אותה ב-Cloud Run. כדי לוודא שהיא פועלת עצמאית בצורה תקינה, נפעיל כמה הרצות – באופן יזום ועל ידי Trigger.
רק נזכיר כי Cloud Run פועל באמצעות קונטיינרים. את המשימה שלנו נפעיל באמצעות הקונטיינר שנמצא ב-Artifact Registry.
Cloud Run מגביל את השימוש שלנו עד להקצאת 8 מעבדים למשימה. לכן Cloud Run מתאים להרצת החלק הראשון של התהליך, שצורך מעט משאבים. החלק השני מגיע לניצול מיטבי בהקצאה של 16 מעבדים. אם כן, לא נוכל להריץ אותו על Cloud Run, כי זה יקח יותר מדי זמן.
Cloud Batch Job:
רכיב זה יכול להוות משהו שבין Workflow ל-Cloud Run. כל זה במובן שהוא יכול להריץ סדרה של משימות, וגם יכול להריץ סקריפט או קונטיינר. אבל בשביל זה הוא מפעיל מכונה וירטואלית. כלומר, הוא לא מופיע כשירות Serverless כמו שני אלה שהזכרנו לעיל.
לכן צריך לשים לב למשאבים שמקצים לפעולה כזו כאשר מגדירים אותה. מצד אחד, ישנו הצורך של המשימה במשאבי מחשוב. מצד שני, הצורך שלנו שלא להקצות כמות מופרזת ויקרה של משאבים. צריך למצוא את האיזון בין שני צרכים אלה.
ניתן להגדיר משימה שכזו דרך לוח הניהול, אבל משם ניתן להריץ רק משימה חד פעמית. אם תהיה לנו עבודה או תהליך שנרצה להפעיל באופן מחזורי וקבוע, נהיה חייבים ללמוד להפעיל את זה באמצעות JSON.
במקרה שלנו נשתמש ב-JSON הבא:
{
"taskGroups": [
{
"taskSpec": {
"runnables": [
{
"container": {
"imageUri": "imageUri": "me-west1-docker.pkg.dev/yosi-test-dsfsdf/serverless/wrf:latest",
"entrypoint": "/bin/bash",
"commands": [
"-c",
"/tmp/data-bucket/WRF/Process/WRF.sh"
],
"volumes": ["/tmp/data-bucket:/data-bucket"]
}
}
],
"volumes": [
{
"gcs": {
"remotePath": "data-bucket"
},
"mountPath": "/tmp/data-bucket"
}
],
"computeResource": {
"cpuMilli": 16000,
"memoryMib": 32768
},
"maxRetryCount": 0,
"maxRunDuration": "9000s"
},
"taskCount": 1,
"parallelism": 1
}
],
"allocationPolicy": {
"instances": [
{
"policy": {
"machineType": "e2-custom-16-32768",
"bootDisk": {
"type": "pd-ssd"
}
}
}
],
"network": {
"networkInterfaces": [
{
"network": "projects/yosi-test-dsfsdf/global/networks/test",
"subnetwork": "projects/yosi-test-dsfsdf/regions/me-west1/subnetworks/test",
"noExternalIpAddress": true
}
]
}
},
"logsPolicy": {
"destination": "CLOUD_LOGGING"
}
}כדאי להעתיק את ה-JSON לעורך קוד וללמוד את המבנה שלו.
מבנה ה-JSON:
taskGroups – כאמור, Batch גם הוא יכול להפעיל סדרה של פעולות. אם כי כרגע נתתי לו להפעיל משימה אחת בודדת. לכן אנו מגדירים עבור Batch קבוצת משימות. כל משימה בקבוצה מכילה את המאפיינים שלה, את ההגדרות שלה, ואת המשאבים שמקצים לצורך פעולה זו.
taskSpec – כאן הגדרנו פעולה אחת, כאשר בסעיף runnable הגדרנו שתרוץ באמצעות קונטיינר. בסעיף זה ניתן גם להגדיר ריצה של סקריפט. היות והגדרנו קונטיינר, נצטרך להגדיר את הפקודה שתרוץ בקונטיינר עם הפעלתו. אפשר לא להגדיר כלום, אם לקונטיינר מוגדרת פעולת ברירת מחדל שהוא מבצע עם הפעלתו – וכמובן, אם זו הפעולה שנרצה שהקונטיינר יבצע.
volumes – אנחנו יכולים להצמיד רכיבי אחסון למכונה שעליה רץ ה-Batch. במקרה שלנו הגדרנו הצמדה של דלי אחסון.
חשוב לשים לב!
ניתן לראות שיש לנו פעמיים את הסעיף volumes – פעם אחת בהגדרה של המשימה, ופעם שניה בהגדרה של הקונטיינר שהמשימה מריצה.
לאחרונה גוגל שינו את תצורת העבודה של Batch. לכן לא נוכל להציב את הדלי בכל נתיב שנרצה בתוך הקונטיינר, כי הקונטיינר מופעל בתוך המכונה של ה-Batch עם משתמש רגיל ולא עם המשתמש root. אפשר להכריח הרצה בתוך המכונה של ה-Batch כ-root, אבל זה לא מומלץ מטעמי אבטחת מידע.
הפתרון:
- מגדירים הצבה של הדלי בתיקיית /tmp של המכונה, שהיא תיקיה זמנית וגם למשתמש פשוט יש הרשאות קריאה עליה. כך עולה הדלי למערכת הקבצים של המכונה הזמנית של ה-Batch.
- מוסיפים שורה בהגדרות הקונטיינר שמגדירה Volume עבור הקונטיינר. שורה זו מקבילה ל-Flag v בפקודת docker run. כך מציבים נתיב במכונה שמריצה את הקונטיינר, לנתיב בתוך הקונטיינר.
computeResource – בשלב הבא אנחנו מגדירים את משאבי המחשוב שאנחנו מקצים עבור אותה משימה. במקרה שלנו זו מכונה מותאמת אישית של 16CPU, 32GB Memory. כל אלה באים מתוך כלל המשאבים שניתנו למכונה שעליה רץ ההליך של Batch. אז צריך לשים לב לא לתת עבור משימה, יותר משאבים ממה שזמין באותו רגע או באופן כללי.
maxRetryCount – לאחר מכן אנחנו מגדירים כמה פעמים התהליך ינסה לבצע שוב את הפעולה במקרה של כשל.
maxRunDuration – מגדיר את משך הזמן המקסימלי שלאחריו התהליך יכבה את המכונה גם אם העבודה לא הסתיימה.
allocationPolicy – כאן מגדירים את המכונה שעליה רץ התהליך. במקרה שלנו הגדרנו מכונה מותאמת אישית עם 16 מעבדים ו-32GB זכרון. כמו כן הוגדר שדיסק ברירת המחדל של המכונה יהיה דיסק SSD, עבור ביצועי קריאה-כתיבה טובים יותר.
network – כאן מגדירים באיזו רשת תשב המכונה. אם לא מוסיפים את הסעיף הזה, Batch יציב את המכונה ברשת default. אם הסרתם את רשת default מהפרויקט ואין הגדרת רשת, תתרחש שגיאה ולא תעלה מכונה.
logsPolicy – כאן הוגדרה שליחת לוגים רגילה. צריך לשים לב שאותה שליחת לוגים זורקת המון זבל לרישום הלוגים. כי יש agent שכל הזמן בודק שה-batch עדיין רץ בתוך המכונה, וכל הבדיקות שלו נרשמות ללוג.
הרצת המשימה:
עכשיו שאנחנו מבינים את המבנה של Batch JSON, נוכל להפעיל משימה כזו באמצעות פקודת gcloud. כמובן, יש עוד סעיפים שאפשר להכניס, וחלק ממה שהכנסתי אפשר לוותר עליו בהתאם לנסיבות.
הפקודה:
gcloud batch jobs submit wrf-batch --config path\WRF-Batch.json --location me-west1 --project yosi-test-dsfsdfבהנחה שהוזן נתיב תקין ל-JSON תקין של batch, ובהנחה שהזהות שמריצה את הפקודה בעלת הרשאות להריץ Batch, התהליך יתחיל לעבוד.
עם תום התהליך, הרישום שלו ישאר זמין לתקופה מסוימת לצורך מעקב וניטור, ולאחר מכן ימחק. אין אפשרות להפעיל שוב את אותה המשימה.
- ניתן לשים לב כי הלוגים של הרצת Batch מכילים המון שורות ספאם כאלה. GCP Batch מריץ משימות על מכונה. לכן הוא פורש את המכונה עם Agent שיודע להגדיר ולהפעיל את המשימות בתוכה. לאורך כל התהליך GCP Batch מוודא את זמינותו ותקינותו של הסוכן. כך הוא מנטר את הריצה התקינה של השלבים השונים, ואת הישום של השלבים הבאים.
- ברוב המקרים נרצה לסנן את הלוגים של הבדיקות האלה, ולכן נכניס בשורת הסינון את התוכן הבא:
NOT "Server response for instance" AND NOT "report agent state"GCP Workflow:
כעת שיש לנו רכיבים שפועלים בצורה תקינה כל אחד לעצמו, נרצה להכניס את כולם לתהליך סדור. את התהליך נוכל להפעיל באמצעות Trigger מסוגים שונים. כך מגדירים את התהליך לרוץ בתזמון קבוע או בתגובה לאירועים שונים.
אתן כאן YAML לדוגמה של Workflow:
main:
steps:
- set-date:
assign:
- date: ${text.substring(time.format(sys.now()), 0, 16)}
- shorted: ${text.replace_all(text.replace_all(date, "T", "-"), ":", "-")}
- wrf-prepare:
call: googleapis.run.v1.namespaces.jobs.run
args:
name: "namespaces/<project-num>/jobs/wrf-prepare"
location: me-west1
result: job_execution
- get-batch-config:
call: googleapis.storage.v1.objects.get
args:
bucket: "data-bucket"
object: "WRF%2FProcess%2FWRF-Batch.json"
alt: "media"
result: object_data
- wrf-batch:
call: googleapis.batch.v1.projects.locations.jobs.create
args:
parent: "projects/yosi-test-dsfsdf/locations/me-west1"
body: ${object_data}
jobId: ${"wrf-" + shorted}
connector_params:
timeout: "9000"
result: createAndRunBatchJobResponseכדאי להעתיק את ה-YAML לעורך קוד ולהתבונן במבנה.
הסבר:
זו דוגמה להליך פשוט בן ארבעה שלבים. לכל שלב יש שם, ואז מגדירים את התכונות שלו.
set-date – זה השלב הראשון ובו אנחנו מגדירים משתנים. המשתנה שנוצר בסוף מכיל מחרוזת שמספרת לנו (על פי תבנית נקובה), מה היתה השעה בזמן בו נוצרה המחרוזת.
wrf-prepare – בשלב השני התהליך מבצע קריאה ל-API של Cloud Run כדי להפעיל משימה. שם נותנים לו את הנתיב למשימה המסוימת שנרצה להפעיל. לבסוף מוסיפים את התוצאה שהתהליך ימתין לה, לפני שיעבור לשלב הבא.
get-batch-config - בשלב השלישי מתבצעת קריאה לדלי אחסון, כדי לקרוא ממנו את ה-JSON שמגדיר את ה-Batch.
wrf-batch – בשלב הרביעי והאחרון מתבצעת קריאה ל-API של Cloud Batch. שם מוגדרת יצירת משימה, עם הגדרות מתוך ה-JSON שנאסף בשלב הקודם.
– כאן בא לידי ביטוי המשתנה עם התאריך שנוצר בשלב הראשון. שכן אם אנחנו יוצרים באופן קבוע תהליכי batch, לא נוכל לתת להם את אותו השם. לכן כדאי להוסיף חותמת זמן שתבדיל כל ריצה מהאחרות.
חשוב לשים לב:
- השורה שבה מוגדר "result" אינה חובה. אם לא נגדיר שורה זו, ברגע שיופעל תהליך ב-Cloud Run או Batch, לא תהיה לנו בקרה על הפעולה שלו. כלומר, ההפעלה שלו מתוך ה-Workflow תהיה בבחינת "שגר ושכח". אם פעולת ההפעלה הצליחה, אותו שלב ב-Workflow הסתיים והתהליך ממשיך לשלב הבא. אם השלב הבא תלוי בהשלמת התהליך הנוכחי, חובה להוסיף את השדה "result".
- צריך לשים לב לתצורה המיוחדת שבה כותבים את הנתיב לקובץ שבתוך הדלי. התהליך מתקשה לקרוא את הלוכסנים של הנתיב.
- כמו כן ישנו הביטוי alt שבו הערך media. קריאה רגילה לאובייקט מתוך דלי אחסון, מחזירה json שמכיל את ה-metadata של האובייקט. לא את תוכן האובייקט עצמו. לכן כדי לקבל את תוכן האובייקט עצמו, נצטרך לציין את זה כאמור. כתוצאה, אנחנו מקבלים לתוך משתנה את תוכן ה-JSON.
- חשוב לשים לב למאפיין connector_params. בכל פעם שהתהליך קורא ל-API כלשהו, זה מתבצע באמצעות Connector שמקשר לאותו API. כברירת מחדל, החיבור לאותו API נשאר בחיים רק חצי שעה. לכן כשנפעיל תהליך ארוך ונרצה לוודא כי הסתיים בהצלחה, נצטרך להגדיר לו מפורשות את משך הזמן המקסימלי שבו החיבור ישאר פתוח. (במקום סתם להפעיל קונטיינר ב-Cloud Run או Batch בלי שה-Workflow יוודא שההפעלה הסתיימה בהצלחה). לאחר מכן אותו השלב יסגר גם אם המשימה לא הסתיימה. אם המשימה לא הסתיימה, ביצוע השלב יחשב ככשלון. כתוצאה מכך, התהליך כולו יסתיים בכשלון – אלא אם כן נוסיף לתהליך תנאי שיודע להתמודד עם הכשלון.