בסיס – גיבוי, שחזור והעברת שרתים
הקדמה:
מעבדה זו נכתבה כהמשך למעבדה ראשונה שעסקה בהקמת פרוייקטים, רשתות ושרתים ראשונים בסביבת הענן של גוגל.
במעבדה זו ניתן להתנסות בגיבוי ושחזור דיסקים לשרתים, ושימוש ראשוני ב-CLI של GCP דרך PowerShell. כמו כן ניתן לראות כיצד להעביר/להעתיק מכונות בין פרוייקטים או אפילו בין Zones באותו הפרוייקט ובאותו ה-Region.
בכל המאמרים שלי נהגתי לפי התפישה שעדיף לתת חכות ולא דגים. לכן תמיד נכנסתי להסברים מעמיקים על פעולות שונות – כל זה כדי שהקורא יבין לעומק איך הדברים עובדים. משעה שאדם לומד איך הדברים פועלים, הוא יודע ליישם אותם באופן כללי ובמגוון רחב של מקרים, ולא רק לחזור כמו תוכי על דוגמה ספציפית שהציגו במדריך.
על פי תגובות שקיבלתי ממשתמשים מתקדמים יותר, החלטתי לקחת את דרך האמצע. את המדריך/מעבדה השתדלתי ליצור בצורה מעט יותר תמציתית, ואת ההסברים המורחבים והמפורטים הוספתי בנספחים בסוף – למי שירצה.
במעבדה זו ניתן לרכוש את הידע ולהתאמן בנושאים הבאים:
1. יצירת פרופיל לגיבוי דיסקים.
2. התקנת Google Cloud CLI
3. שימוש בפקודות gcloud בסיסיות.
4. שחזור/יצירת מכונות מתוך Snapshots.
5. העברת מכונה בין פרוייקטים באמצעות Snapshot.
יצירת פרופיל גיבוי:
בלוח הניהול של GCP, הולכים ל-Compute Engine >> Snapshots.
כרגע הכל ריק, כי עוד לא עשינו כלום.
אז נלחץ למעלה CREATE SNAPSHOT SCHEDULE, כדי ליצור לנו תכנית גיבוי עבור הדיסקים של המכונות.
- נשאיר לו את השם כ-schedule-1
- נוודא שהמיקום שלו זה במחוז תל אביב
- נשאיר אותו על Regional – כי אנחנו לא מתכננים פה איזה מערך DR וחבל על העלויות הנוספות
- אותו Regional צריך להיות בתל אביב
- נבחר בתדירות תזמון לפי שעות
- חזרה כל שעה – כל שעה יווצר Snapshot חדש
- מחיקה אוטומטית כעבור יום
- Deletion rule – לסמן מחיקה של Snapshot ישן יותר מיום אחד
- ללחוץ CRAETE
הסבר:
אז יצרנו תכנית שמנפיקה Snapshot כל שעה ולא משאירה אותם יותר מיום, כאשר אותם Snapshots נשמרים רק מקומית ברמת ה-Region. לא לדאוג, הם מגובים ובנויים לשרידות טובה בתוך ה-Region.
הסיבה בשלה אנחנו יוצרים Snapshot כל שעה, היא בגלל שמדובר בסביבת מעבדה. לכן גם נרצה לראות מהר שנוצרים Snapshots, וגם אולי נרצה לשחזר לפעמים דיסקים שהשתנו, ובגלל שמדובר בסביבת מעבדה – כמות השינויים דחוסה בזמן קצר יותר.
כעת נלך ל-Disks (עדיין ב-Compute Engine) ונכנס להגדרות הדיסק של instance-1. שם נלחץ EDIT. בחלון העריכה נראה שיש לנו הגדרה של Snapshot schedule, שם נוסיף את התכנית שהרגע יצרנו, ואז נשמור.
לחזור על הפעולה הזו עבור כל הדיסקים.
… רגע!
לא מייגע לבצע את אותה הפעולה שוב ושוב על כל הדיסקים?
אז בואו ונלמד לבצע את הפעולה באמצעות פקודות דרך PowerShell. כך נוכל לבצע סדרות של פעולות באמצעות הגדרה אחת.
התקנת GCP CLI עבור PowerShell:
פותחים כמנהל חלון PowerShell (במחשב שממנו עובדים) ומריצים בפנים את הפקודה הבאה:
(New-Object Net.WebClient).DownloadFile("https://dl.google.com/dl/cloudsdk/channels/rapid/GoogleCloudSDKInstaller.exe", "$env:Temp\GoogleCloudSDKInstaller.exe"
& $env:Temp\GoogleCloudSDKInstaller.exe)מיד תעלה חלונית התקנה, next..next…next… אין צורך לשנות כלום.
זה יקח כמה דקות עד שההתקנה תסתיים, ואז בחלונית הסופית אפשר להוריד את כל תיבות הסימון, ואז ללחוץ Finnish.
לסגור את חלון ה-PowerShell ולפתוח מחדש כאדמין, ואז להזין בפנים את הפקודה – gcloud init.
המחשב יבקש לפתוח דפדפן, ושם יבקש להתחבר לחשבון ב-GCP. אז תעלה בקשה לאשר גישה לחשבון GCP באמצעות Google Cloud SDK. לאחר האישור (צריך לגלול למטה כדי למצוא לחצן Allow) – נעבור לדף שיבשר לנו כי אומתה הגישה שלנו עבור gcloud cli.
חוזרים ל-PowerShell ושם אנחנו מתבקשים לבחור פרוייקט ברירת מחדל. לאחר מכן הוא ממשיך לרוץ ולהגדיר את המאפיינים של החיבור, ומסיים.
ועכשיו, רבותי – PowerShell! (חוכך ידיים בציפיה).
לפתוח PowerShell-ISE כמנהל, ולהדביק בתוך עורך הקוד שלו את הטקסט הבא:
$disks = gcloud compute disks list --format=json | ConvertFrom-Json
$disks | %{gcloud compute disks add-resource-policies $_.Name --resource-policies schedule-1 --zone $_.zone} – הסבר מפורט על הפקודות וכיצד הן עובדות – יבוא בנספחים א' וב' בסוף.
שחזור/יצירת מכונה חדשה מתוך Snapshot:
אפשרות א':
1. ב-Compute Engine הולכים ל-Snapshots ובוחרים את זה שממנו רוצים לשחזר.
ניתן לסנן את הרשימה דרך הפילטר למעלה, עם חיפוש לפי ערכים המופיעים בכל העמודות בטבלה.
2. לוחצים על אותו סנאפשוט כדי להכנס לדף שלו, ושם למעלה יש לחצן CREATE INSTANCE.
3. מפה נפתח דף של יצירת מכונה, כאשר אפשר לערוך ולהתאים את כל המאפיינים הרגילים, רק סוג הדיסק ומערכת ההפעלה כבר נבחרו – דיסק שנוצר מתוך ה-Snapshot.
אפשרות ב':
1. אפשר גם ללכת ל-VM instances ומשם ללחוץ על CREATE INSTANCE, ושם בחלק של Boot disk ללחוץ על CHANGE.
2. בחלונית שתקפוץ ברירת המחדל היא לשונית של PUBLIC IMAGES – שם ניתן לבחור מערכת הפעלה מתוך Images שמציעה GCP. אבל במקרה שלנו נעבור ללשונית של SNAPSHOTS ונבחר את זה המתאים, והוא יהווה את הדיסק ומערכת ההפעלה למכונה שתווצר.
לאחר בחירת שאר מאפייני המכונה החדשה, לוחצים על CREATE ויש לנו מכונה שנוצרה מתוך snapshot.
יצירת מכונה בפרויקט ב' מתוך Snapshot בפרויקט א':
מי שיבחן את האפשרויות שניסינו עד עכשיו, יראה שבלוח הניהול של GCP, כאשר אנו מנסים לבנות דיסק/מכונה מתוך Snapshot, אנו מקבלים רשימה של ה-Snapshots שקיימים אך ורק בפרוייקט שבו אנו נמצאים באותו הרגע.
כדי ליצור מכונה בפרוייקט אחר, צריך להשתמש בפקודות gcloud באחת משתי דרכים:
א. ליצור מכונה בפקודת gcloud, עם flag שמציין שהמכונה נוצרת מתוך snapshot – והדגל הזה מכוון לאותו snapshot בפרויקט השני.
ב. ליצור snapshot בפקודת gcloud, כאשר ה-snapshot נוצר מדיסק בפרוייקט א', ומגיע לפרוייקט ב'.
ברגע שה-Snapshot בפרוייקט ב', אפשר ליצור ממנו מכונה באותו פרוייקט, באמצעות לוח הניהול או באמצעות שורת הפקודה.
לפני שננסה להקים מכונה, נצטרך שתהיה לנו רשת בפרוייקט ב':
1. בתפריט הפרוייקטים (למעלה משמאל, ליד איפה שכתוב Google Cloud) לעבור לפרויקט השני שהוקם במעבדה הקודמת.
2. בפרויקט השני, הולכים ל-VPC network >> VPC networks.
3. לוחצים למעלה CREATE VPC NETWORK.
4. למלא לפי הפרטים הבאים:
א. שם – vpc-4
ב. Subnet creation mode – Custom
ג. להוסיף subnet בשם subnet-4, שתהיה במחוז ת"א בטווח כתובות של 10.0.40.0/24
5. ללחוץ CREATE.
הפקודה עבור אפשרות א':
עבור פקודה זו צריך את הנתיב ה(כמעט) מלא עבור אותו snapshot. את הנתיב אפשר להשיג בשתי דרכים:
הדרך הראשונה:
1. למצוא את ה-Snapshot ולהכנס לדף שלו.
2. ללחוץ שם למטה על EQUIVILENT REST.
3. בחלונית שנפתחת, למצוא שם את השורה שמכילה את הערך selfLink ולהעתיק את הערך.
4. להזין את הערך בפקודה תחת הדגל source-snapshot.
הדרך השניה:
1. למצוא סינון ברור עבור השם של ה-Snapshot. אם זה נוצר באופן אוטומטי כמו על פי תבנית הגיבויים שיצרנו, יש לו בסוף איזה מס' סידורי יחודי.
2. אם נמצא מס' סידורי, להכניס אותו כמסנן (~) לפקודה שמבקשת רשימה של snapshots. אם אין מס' סידורי, להכניס את השם המלא והמדויק של אותו snapshot כמסנן (=).
3. מהפקודה להוציא פלט דומה לזה שהוצאנו בדרך הראשונה ולשים במשתנה.
4. להזין את המשתנה בפקודה תחת הדגל source-snapshot.
הפקודה (יחד עם פקודת הסינון עבור הדרך השניה):
$lnk = (gcloud compute snapshots list --format="value(selfLink)" --filter="name~299u9w6x").Substring(38)
gcloud compute instances create from-snapshot `
--source-snapshot=$lnk `
--no-address `
--network="vpc-4" `
--private-network-ip="10.0.40.40" `
--subnet="subnet-4" `
--zone="me-west1-a" `
--project="yostest-2" `
--machine-type=e2-micro– בדרך זו ניתן גם להעתיק/להעביר מכונה מ-Zone-a ל-Zone-b.
הפקודה עבור אפשרות ב':
כאן הפקודה די פשוטה. בשורה הראשונה מכניסים את שם הדיסק שממנו לוקחים snapshot, כדי שיקח את ה-selfLink שלו. ובפקודה עצמה צריך רק לשים את שם פרוייקט היעד.
הפקודה:
$lnk = (gcloud compute disks list --format="value(selfLink)" --filter="name~instance-1").Substring(38)
gcloud compute snapshots create snaptest `
--source-disk=$lnk `
--project="yostest-2" `
--storage-location=me-west1 למחוק את המכונה שנוצרה באפשרות א' ואת ה-snapshot שנוצר באפשרות ב' מתוך הפרוייקט השני.
יצירת דיסק מתוך Snapshot:
דרך נוספת לטפל בעניין היא באמצעות יצירת דיסק מתוך Snapshot. את הדיסק ניתן להצמיד למכונה החדשה בעת הקמתה.
באמצעות לוח הניהול:
1. הולכים ל-Compute Engine >> Snapshots
2. בוחרים ב-Snapshot הרצוי ובלחיצה נכנסים לדף שלו
3. לוחצים למעלה על CREATE DISK
באמצעות gcloud:
$lnk = (gcloud compute snapshots list --format="value(selfLink)" --filter="name~7frlopcu").Substring(38)
gcloud compute disks create disktest `
--source-snapshot=$lnk `
--zone="me-west1-a" שחזור מכונה קיימת מתוך Snapshot:
1. Compute Engine >> VM instances >> instance-1.
2. לוודא שהמכונה כבויה. אם לא, ללחוץ למעלה על STOP ולחכות עד שתכבה.
3. ללחוץ למעלה על EDIT.
4. בדף העריכה שנפתח, לרדת עד לאזור של Storage, שם יש לחצן DETACH BOOT DISK, ללחוץ עליו.
5. מיד במקומו יופיע לחצן CONFIGURE BOOT DISK. ללחוץ עליו.
6. תיפתח חלונית צד, בה צריך לעבור ללשונית של SNAPSHOTS.
7. לבחור את ה-Snapshot המתאים.
8. ללחוץ SELECT כדי לקבוע את הבחירה של ה-Snapshot הזה בתור מקור לדיסק-מערכת-הפעלה.
9. בדף העריכה של המכונה ללחוץ על SAVE.
10. להפעיל מחדש את המכונה.
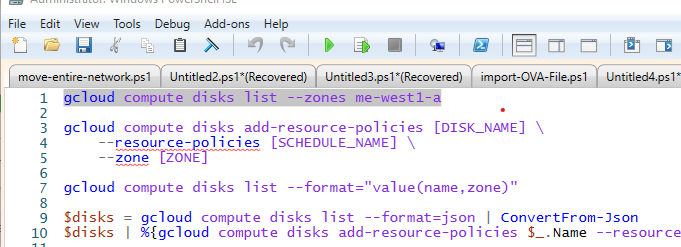
נספח א' – ניתוח ולמידה של מבנה פקודות gcloud:
ראשית, יש לפתוח PowerShell ISE ולהעתיק לעורך הקוד שם את השורות הבאות:
gcloud compute disks list
gcloud compute disks add-resource-policies [DISK_NAME] \
--resource-policies [SCHEDULE_NAME] \
--zone [ZONE]
gcloud compute disks list --format="value(name,zone)"
$disks = gcloud compute disks list --format=json | ConvertFrom-Json
$disks | %{gcloud compute disks add-resource-policies $_.Name --resource-policies schedule-1 --zone $_.zone} פקודות CLI של GCP מורכבות מכמה אברים עיקריים:
1. הכלי שבו משתמשים. ב-SDK של גוגל יש כלים כמו gcloud, gsutils ועוד.
2. המשאב שאליו פונים. זה יכול להיות compute instances, compute disks, או compute network עבור VPC.
3. מה נרצה לעשות עם המשאב הזה. list – כדי להציג רשימה, create – כדי ליצור אחד כזה וכו'.
4. מאפיינים ומסננים שנועדו למקד את הפקודה. נקראים flags.
יש כמה flags שניתן לשים ברוב הפקודות כמו project או zone, אם כי לא תמיד הם הכרחיים. יש כאלה שאופייניים לפקודות מסויימות, והפקודה חייבת את הנתונים האלה כדי לדעת כיצד ועם מה לעבוד.
פעמים רבות לצורך עבודה עם ה-CLI של GCP, נרצה להוציא רשימה של נתונים על משאבים שונים. כמו רשימה של מכונות וירטואליות, דיסקים, רשתות, פרופילים וכו'.
נחזור לפקודות שניתנו לעיל:
שורה 1 – כאן יש את הפקודה הבסיסית שנועדה להציג את רשימת הדיסקים. כברירת מחדל היא מציגה את כל מה שיש בפרויקט, אבל אם נוסיף את הדגל "—zone me-west1-a", נקבל רק את הדיסקים שיש בפרוייקט ברירת המחדל שלנו, ב-Zone-a.
אפשר לסמן את כל שורה מס' 1, ואז ללחוץ למעלה על הלחצן שנראה כמו לחצן הפעלה ירוק מעל דף/מסמך:
לחצן זה מפעיל מתוך הקוד רק את הטקסט המסומן.
אם נריץ את הפקודה בלי הסינון של zone, נקבל למטה בטרמינל פלט כזה:
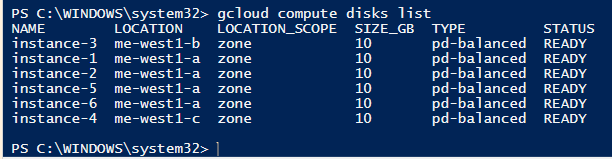
אבל זה לא מספיק.
את רשימת הדיסקים אנחנו צריכים, כדי לדעת איזה דיסקים יש לנו, ועל איזה מהם נרצה להחיל את תכנית הגיבוי שיצרנו קודם. בשביל זה נצטרך לבודד נתונים כמו שם הדיסק, או באיזה zone הוא נמצא, או איזה סוג דיסק זה.
נביט לרגע בפקודה הבאה, כפי שהיא באה מתוך המסמכים של GCP.
שורות 3-5
זו פקודה שמצמידה לדיסק את תכנית הגיבוי. התחביר מופיע כפי שניתן להפעיל אותו מתוך מכונת לינוקס.
– פקודות gcloud מופיעות במסמכי gcp בתחביר המתאים למכונות לינוקס, מאחר ובכל מכונת לינוקס שבאה מוכנה מתוך ה-Images של GCP (ולא למשל מכונה שהעברתם כפי שהיא לענן באמצעות מיגרציה או קובץ OVA), מותקן בה כבר ה-SDK של GCP.
– כמו כן, תמיד ניתן להריץ פקודות gcloud מתוך טרמינל שנפתח בלוח הניהול של GCP. הלחצן להפעלת הטרמינל נמצא למעלה מימין (ליד העיגול של ההודעות) והוא פותח טרמינל למכונת Debian עם שטח אחסון של עד 5GB, שבו ניתן לעבוד בתצורת טרמינל על סביבת הענן.
אבל אני מעדיף לעבוד מתוך PowerShell ולא מתוך הטרמינל, כי אני מעדיף את ה-Scripting של PowerShell שהוא הרבה יותר חזק מה-Scripting של bash – שזה ה-CLI של לינוקס.
הלוכסנים שניתן לראות בפקודה בסוף שתי השורות הראשונות, נותנים את האפשרות לעבור שורה בלי לשבור את הרצף. כלומר – בעין של המשתמש שכותב את הפקודה, הוא עבר שורה וזה נראה יותר מסודר, אבל מבחינת המכונה מדובר בפקודה אחת.
מעבר שורה
מבחינת התחביר של PowerShell, במקום הלוכסן הזה משתמשים בגרש שנמצא מעל לחצן tab (חולק כפתור עם נקודה פסיק ועם סימון טילדה [~]) – הגרש הבא: `. כשהמקלדת על אנגלית, הגרש הזה הוא ברירת המחדל של הכפתור הזה.
– הגרש הזה שונה מהגרש שמופיע בעברית בלחצן של Q, או באנגלית בלחצן עם הגרשיים והפסיק העברי. לא להתבלבל ביניהם, מה שעובד עם האחד מבחינת תחביר – לא יעבוד עם השני.
בהזדמנויות אחרות נראה כיצד אנחנו משתמשים באותו גרש כדי להציג בצורה נוחה לעין פקודות ארוכות עם הרבה מאפיינים (flags). אבל כרגע זה לא נחוץ, ותוכלו לראות שבהמשך בשורה 10, פשוט צמצמתי את הפקודה לשורה אחת.
נבחן את הרכב הפקודה שמצמידה את פרופיל הגיבוי לדיסק
נוכל לראות שהיא מורכבת מן הפקודה עצמה, ושלושה נתונים שצריך להזין בפנים – שם הדיסק, שם פרופיל הגיבוי, ה-zone שבו נמצא הדיסק. מה שאומר שאנחנו צריכים לעבד את הנתונים שקיבלנו מהפקודה הקודמת (disks list), ולבודד מכל דיסק את השם וה-zone שלו.
נספח ב' – עבודה עם נתונים מתוך list של GCP:
מי שיכניס את הפלט של הפקודה משורה 1 לתוך משתנה וינסה לעבוד איתו, יגלה שמדובר בשורות של טקסט. כלומר, המשתנה שמקבל את הפלט הופך למערך/רשימה, שכל איבר בו מכיל שורה אחת משורות הפלט. השורה הראשונה מכילה את הכותרות של העמודות השונות בטבלת הנתונים הזו.
מיד נראה למה קשה לעבוד עם זה:
נוסיף לעורך הקוד של PowerShell ISE בשורה 12 את הפקודה הבאה, ואז נסמן את השורה ונפעיל אותה:
$list = gcloud compute disks list כעת המשתנה $list יתן לנו את כל הטבלה, בעוד ש-$list[0] יתן לנו את שורת הכותרות, ומשם $list[1] יתן את הנתונים על הדיסק הראשון ברשימה, $list[2] את נתוני הדיסק השני וכן על זו הדרך.
כדי לבודד את שם הדיסק, נצטרך קצת להסתבך ולפרק את המחרוזת שמרכיבה את $list2. למשל:
($list[2].Split(" ") | ?{$_.Length -gt 0})[0] מה הלך פה עכשיו? הבה נשחק.
היות ו-$list2 מהווה שורת טקסט, נהיה חייבים לשבור אותה כדי להגיע למקטע מסויים, לפי תבנית הטבלה שאנחנו מכירים מהפלט הראשוני.
באמצעות המתודה split אנחנו שוברים את שורת הטקסט לחלקים, כאשר כל רווח מהווה נקודה שבה השורה נשברת שוב ויוצרת חלק חדש. היות ושבירה של טקסט על פי רווחים יכולה לתת הרבה חלקים ריקים, מתבצע לאחר מכן סינון דרך pipline, שבוחר מכל החלקים רק את אלה שאורכם גדול מ-0. כלומר – מכילים טקסט אמיתי.
כל הפקודה הזו תחומה בתוך סוגריים, כדי להפוך את הפלט של הפקודה לאובייקט שניתן להתייחס אליו ולעבוד איתו ישירות – במקום להכניס לתוך משתנה ואז לעבוד מול המשתנה.
הפלט של הפקודה מכיל רשימה של הערכים שהיו באותה השורה. כאשר הערך הראשון (אינדקס 0) מכיל את שם הדיסק – כפי רשום בפקודה שניתנה לעיל, והערך השני (אינדקס 1) מכיל את ה-zone.
כל זה טוב ויפה. ובמקרה שלנו, נוכל להתייחס לרשימת הדיסקים כאל $list[1..($list.Count)]
ואז נוכל לרוץ על הרשימה הזו באמצעות לולאה או pipeline, ועל כל איבר ברשימה הזו נפעיל את הפקודה שמצמידה את פרופיל הגיבוי לדיסק הספציפי, כאשר את נתוני הדיסק נציג באמצעות הפקודה שבה השתמשנו קודם כדי לשבור את השורה ולבודד כל נתון לעצמו.
וככה זה יראה:
$list[1..($list.Count)] | %{ ` gcloud compute disks add-resource-policies ($_.Split(" ") | ?{$_.Length -gt 0})[0] `
--resource-policies schedule-1 `
--zone ($_.Split(" ") | ?{$_.Length -gt 0})[1]
} קצת מורכב, וזה יעבוד רק אם נתוני הטבלה מתנהגים בדיוק כפי שצפינו. יהיו מקרים שבהם נוציא רשימות נתונים, ועבור אחד העצמים ברשימה, אחד המאפיינים יהיה ריק. כך שבאותה שורה, על אותו אינדקס ישב מאפיין אחר.
לדוגמה:
בטבלת הפלט שקיבלנו קודם, יש שש עמודות. כאשר העמודה השניה היא ה-zone, ולכן אנחנו מתייחסים לערך שלה בתור אינדקס 1. אם בשורה מסוימת הערך של Location יהיה ריק, היות ואנחנו שוברים מחרוזת טקסט ומתעלמים מהרווחים, נקבל באינדקס 1 את הערך של Location_Scope במקום את הערך של Location. וזה ישבור לנו את הפקודה.
דרך אחרת
אפשר לסנן מראש את הערכים לפי עמודה, וכך נקבל בדיוק את הערך שאנחנו רוצים.
את זה ניתן לעשות באמצעות הדגל –format – כפי שניתן לראות בפקודה בשורה 7. באמצעות format ניתן להציג את הפלט של פקודת list בתצורות מסוימות.
אם נבחר להציג את הפלט לפי ערכים של עמודות מסוימות, הרי שהפקודה משורה 7 מציגה לנו רק את השם של כל דיסק ובאיזה zone הוא נמצא. במצב כזה עדיין נצטרך לשבור מחרוזת טקסט, ולכן במקום רשימה אחת, נשתמש בשני משתנים – אחד מכיל שמות, ואחד מכיל את ה-zone של כל דיסק.
וככה זה יראה:
$diskname = gcloud compute disks list --format="value(name)"
$diskzone = gcloud compute disks list --format="value(zone)" נשים לב לשני דברים:
1. נכון שבטבלה שהוצגה לנו קודם הכותרת של העמודה של ה-zone היתה Location, עכשיו אנחנו רואים שהשם האמיתי של העמודה הוא zone. זה אומר שכדי לבצע סינון פורמט, צריך להכיר את השמות מאחורי הקלעים של כל עמודה.
2. כעת כשאנחנו מקבלים ערך ישיר ולא תצוגה נוחה לעין של DisplayName, אנחנו ממש מקבלים את ה-url המלא עבור כל zone.
היות וכל ה-url הזה מיותר – וגם לא יעבוד בתור נתון לפקודה של הצמדת פרופיל גיבוי לדיסק, נצטרך לפרק את זה. רק שעכשיו נדע שתמיד url של zone נראה אותו דבר. ולכן הפקודה שלוקחת את ה-zone של כל דיסק, תראה ככה:
$diskzone = gcloud compute disks list --format="value(zone)" | %{$_.split("/")[-1]}בעצם הוספנו לפקודה שמוציאה את רשימת ה-zone, pipeline שלוקח את כל האברים ברשימה, שובר אותם בכל מקום שהוא מוצא לוכסן, ונותן לנו מכל אבר את השבר האחרון אחרי כל הלוכסנים.
עם זה אפשר לעבוד. אבל עדיין יש בעיות:
1. אם נרצה לעבוד עם שורה של מאפיינים, ולא רק שנים. עם כמה משתנים ושורות נצטרך לעבוד כדי להגיע לכולם?
2. איך נדע מה השמות האמיתיים של כל עמודה?
שורה 9 – קבלת רשימת משאבים של GCP, בתור אובייקט עם Attributes. בעבודה עם PowerShell, הכי נוח לעבוד מול אובייקטים עם Attributes.
באמצעות קבלת הרשימה בפורמט json, ואז הפיכת ה-json לאובייקט, נדע מיד איזה attributes יש לאובייקט, וכך נוכל לפנות לערך של כל attribute בהתאם.
נסמן את שורה 9 ונריץ את הפקודה. כעת יש לנו רשימת אובייקטים תחת המשתנה $disks.
אם נבחר אחד מן האובייקטים ברשימה ונשים נקודה, זה יתן לנו גישה לרשימת ה-Attributes שלו:
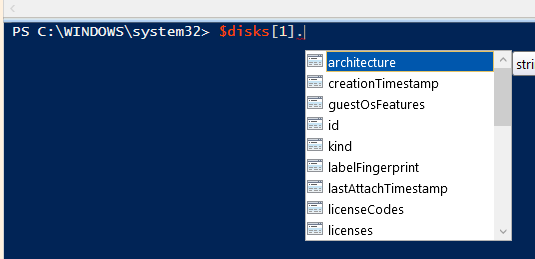
ניתן לראות עכשיו את השמות האמיתיים של כל מאפיין, וגם ניתן לראות שקיבלנו הרבה יותר מאפיינים ומידע עבור כל דיסק, ממה שהוצג לנו קודם בטבלה הפשוטה.
אם כן, נראה שבמקרים מסוימים כמו שלנו, נח יותר לאסוף את הנתונים לאובייקט דרך פורמט JSON.
כעת נריץ את הפקודה משורה 10, ונראה שבטרמינל רצות הודעות על כך שהתעדכנו הפרטים של הדיסקים. אז נחכה בין שעתיים ליום – על מנת שתווצר כמות של snapshots, ואז נמשיך.
סינון פריטים ברשימה המתקבלת:
לאחר שעבר פרק הזמן הנדרש ונוצרו Snapshots עבור כל מכונה, נוכל לקבל רשימה של כולם באמצעות הפקודה הבאה:
gcloud compute snapshots list אז קיבלנו את הטבלה, שהפעם מכילה את העמודות הבאות: NAME, DISK_SIZE_GB, SRC_DISK, STATUS.
ואם נרצה לסנן רק את ה-snapshots של instance-1, נשתמש בדגל הבא – –filter.
למשל, בצורה הבאה:
cloud compute snapshots list --filter="name~instance-1" נראה שבגלל שהשם של ה-snapshot מכיל את השם של המכונה ואת ה-zone שלה (בצירוף חותמת זמן ומס' סידורי), קיבלנו רשימה של כל הפריטים שאצלם יש התאמה לביטוי instance-1.
ניתן להבין שהסימן טילדה (~) מסמן mutch בפילטר של GCP.
שאר הסימנים די מקובלים, עם סימון = עבור התאמה מלאה, סימן קריאה עבור שלילה – כמו =! עבור "אינו שווה", חיצים ימינה ושמאלה עבור ערך שגדול או קטן מ.. וכו'.
אם כן, ננסה לסנן עבור כאלה שיש התאמה ל-Source-Disk שמכיל את הביטוי instance-1:
gcloud compute snapshots list --filter="src_disk~instance-1" לא עובד. למה?
כי שם העמודה שבטבלה לא תואם לשם של המאפיין מאחורי הקלעים. נחזור ל-JSON כדי לבדוק את שם העמודה:
$snap = gcloud compute snapshots list --format=json | ConvertFrom-Json
$snap[1] בפקודה הראשונה אנחנו מכניסים למשתנה את כל הרשימה, כאשר כל פריט ברשימה נכנס כאובייקט עם מאפיינים, שנקלט מתצורת JSON. בפקודה השניה אנחנו מציגים בטרמינל את פריט אינדקס 1 ברשימה (הפריט השני), ובטרמינל נראה את כל המאפיינים של הפריט.
נראה אם כן כי מאחורי הקלעים, השם של המאפיין זה sourcedisk.
ואם נבצע סינון לפי זה, הפעם זה יעבוד:
gcloud compute snapshots list --filter="sourceDisk~instance-1" ניתן להוסיף כמה פילטרים, כאשר מחברים אותם עם הביטוי AND:
gcloud compute snapshots list --filter="sourceDisk~instance-1 AND name~20230706193901" נראה כי למרות שיש לי ברשימה כרגע 18 snapshots עבור instance-1, היות וציינתי עוד פילטר שכולל את חותמת הזמן של אחד מהם – וחותמת זמן זו שייכת רק ל-snapshot-1, התוצאה המסוננת כוללת רק את אותו snapshot ספציפי.
– פורמט ופילטר רגישים לאותיות קטנות וגדולות!
למעשה, ניתן להכניס ביטויים לוגיים בתוך הפילטר, רק צריך לוודא שמילות הקישור מופיעות באותיות גדולות, עם רווחים בין הביטויים ומילות הקישור. ביטויים לוגיים כוללים AND, OR, וגם NOT.
כמובן, נוכל תמיד להכניס הכל לאובייקט דרך JSON, ואז לסנן כפי שמסננים אובייקטים באמצעות pipeline. יש כמה דרכים וכל אחת תהיה נוחה יותר במקרים אחרים.