המדריך הבא מתייחס להסדרת Microsoft SQL Cluster בסביבת הענן של GCP. במקרה של מעבר לענן של מערך קיים, או הקמת מערך חדש, צריך לקחת בחשבון את תצורת הרשת בענן כדי להגדיר נכון את האשכול. הסדרת Always On Availability Group בסביבת GCP מצריכה טיפול מיוחד.
פערים והבדלים:
בסביבת OnPrem ניתן להסתמך על פרוטוקולים בשכבה 2 של הרשת. אלה משמשים לתקשורת בין השרתים ולהקפיץ ביניהם את תפקיד השרת הראשי. כך גם הגדרת כתובות עבור מכונות ברשת, יכולה להעשות מתוך המכונה. המתג שמחזיק את אותה הרשת יזהה את הכתובות החדשות ויפנה אליהן את התעבורה.
בסביבת הענן אין שכבה 2, ומתחת לכל המערכים שנועדו לפשט ולדמות סביבת רשת כפי שאנחנו רגילים אליה, בעצם כל מכונה מקבלת כתובת IP בודדת ברשת מבודדת משלה. בממשק המשתמש נראה subnet בטווח שבו הגדרנו, ואת המכונה תופסת בו כתובת אחת מכל הכתובות הזמינות בטווח. אך מאחורי הקלעים זה עובד אחרת, ולכן הגדרות של אשכולות שרתים ו-LB צריכים לפעמים הגדרות שונות מהרגיל.
לא נתעכב פה על ההתקנה עצמה של שרת MS SQL, או על יצירת Availability Group. כאן נתייחס להתאמה של המערך הקיים לסביבת הרשת של GCP. בניה נכונה של Availability Group בסביבת GCP תחסוך בעיות בהעברת תפקיד השרת הראשי, או בכלל בזמינות האשכול.
המערך:
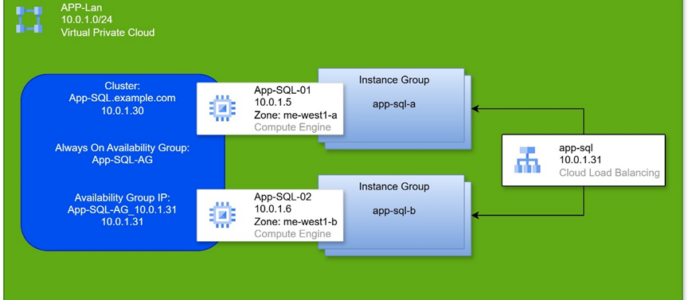
סקירת הרכיבים וההגדרות:
בכל אחד מן השרתים באשכול, ניתן לפתוח את Failover Cluster Manager.
כשהחלון נפתח, נראה בצד שמאל את האשכול וכל הרכיבים שתחתיו. האשכול מופיע כ-FQDN – שם האשכול ואיתו שם הדומיין, אם קיים.
לחיצה על שם האשכול תציג לנו בתחתית החלק האמצעי של החלון, את האשכול כרכיב רשת. לחיצה על הפלוס ליד שם האשכול תציג לנו את כתובת ה-IP שלו.
הרכיב הראשון ברשימה תחת שם האשכול, זה Roles. לחיצה עליו תציג לנו בחלון המרכזי את פרטי ה-Availability Group. השם של הקבוצה, וכתובת ה-IP שלה.
- לשים לב שכתובת האשכול עצמו, שונה מכתובת הקבוצה שמנהלת את ה-Role.
בתחתית החלק האמצעי של החלון (עדיין תחת Roles), ניתן לעבור ללשונית Resources. שם נלחץ על + לצד ה-Server Name ונראה את כתובת ה-IP של הקבוצה. לחיצה כפולה עליה תיתן לנו חלונית מאפיינים של כתובת הקבוצה. לשים לב לשם שקיים שם עבור אותה כתובת IP.
משורת הפקודה:
לפתוח PowerShell כמנהל, ולהזין את הפקודה הבאה:
Get-ClusterResource הפלט מציג כמה רכיבים עיקריים של האשכול. מבחינתנו שני רכיבים חשובים שהם מאפיינים של הקבוצה. האחד הוא רכיב מסוג IP Address שמייצג את הכתובת של ה-Availability Group. הרכיב הזה נושא את השם של הכתובת של ה-Availability Group שראינו קודם בחלונית המאפיינים של כתובת הקבוצה.
השני הוא רכיב מסוג SQL Server Availability Group, והוא נושא את השם של הקבוצה עצמה, כפי שרואים תחת Roles ב-Failover Cluster Manager.
עבודה מול HealthCheck:
אחד הדברים שצריך לעשות, זה לקבע את הפורט שבו הקבוצה מתקשרת כדי לבדוק זמינות של שרת, או מי מהשרתים תופס את התפקיד הראשי באשכול.
נבחר בפורט 48999 שהוא פורט גבוה, אבל לא תפוס על ידי שירותים אחרים. התנגשות בין שירותים יכולה לגרום לבעיות במעבר תפקידים בקבוצה.
נריץ את השורות הבאות כדי לקבוע את הפורט. להציב את הערכים של המשתנים בהתאם לשמות ולכתובת שראינו קודם במאפיינים של ה-Roles ב-Failover Cluster Manager:
$ip_resource_name = << Name of the IP address >>
$load_balancer_ip = << The IP address of the Availability Group >>
[int]$health_check_port = 48999
$avaiability_group = << The name of the Availability Group >>
Get-ClusterResource $ip_resource_name | Set-ClusterParameter -Name 'ProbePort' -Value $health_check_port
Stop-ClusterGroup $avaiability_group
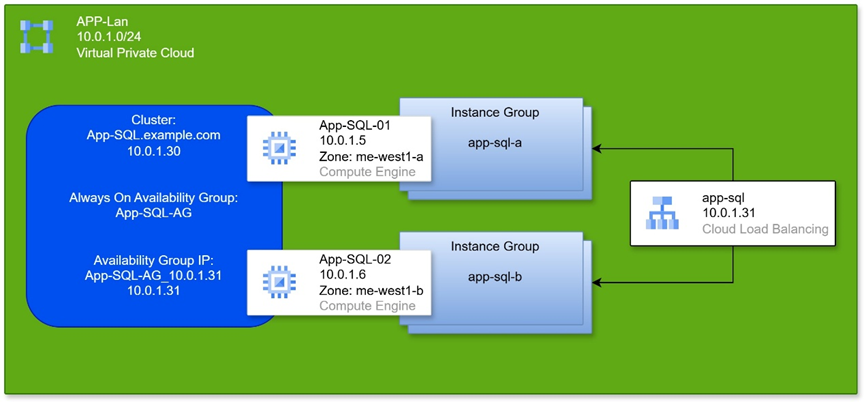
Start-ClusterGroup $avaiability_group או אם ניקח את הדוגמה מהתרשים:
$ip_resource_name = 'App-SQL-AG_10.0.1.31'
$load_balancer_ip = '10.0.1.31'
[int]$health_check_port = 48999
$avaiability_group = 'App-SQL-AG'
Get-ClusterResource $ip_resource_name | Set-ClusterParameter -Name 'ProbePort' -Value $health_check_port
Stop-ClusterGroup $avaiability_group
Start-ClusterGroup $avaiability_group בדיקה ראשונית:
לפתוח SQL Server Management Studio ולהתחבר לאחד השרתים. לאחר החיבור, נסתכל בצד על Object Explorer ונראה את הרכיבים תחת שם השרת שאליו התחברנו.
Always On High Availability >> Availability Groups >> < The availability group name >
שם בסוגריים יופיע התפקיד של אותו שרת בקבוצה. אם הוא ראשי או משני.
קליק ימני על שם הקבוצה יקפיץ תפריט, ונלחץ שם Failover. זה יפתח אשף להקפצת התפקיד הראשי לשרת אחר.
לוודא הקפצה מהשרת הראשי הנוכחי לשרת המשני. ברגע שהשרת המשני הופך לראשי, לוודא היטב שאכן התפקיד קפץ, ולאחר מכן אפשר להקפיץ חזרה.
לאחר בדיקה שההקפצות עובדות כמו שצריך, אפשר להקים Load Balancer שמפנה לקבוצה, ודרכו בעצם פונה כל מי שצריך לגשת למסד הנתונים.
הקמת Instance Groups:
לפני שנוכל להקים LB, צריך להקים Instance Groups שה-LB יוכל להפנות אליהן תעבורה.
כל Instance Group חי בתוך גבולות Zone. לכן כל קבוצה כזו רואה רק שרתים שנמצאים ב-Zone שבו נוצרה.
- בתפריט שלושת הפסים, ללכת ל-Compute Engine ושם ל-Instance groups.
- ללחוץ למעלה על CREATE INSTANCE GROUP.
- בדף שיפתח, ללחוץ משמאל על New unmanaged instance group.
- לתת שם. כדאי לכלול את האות של ה-Zone בשם.
- לבחור מיקום. במקרה שלנו זה אזור תל אביב, ואז Zone a ובקבוצה הבאה Zone b.
- לבחור את הרשת שבה חיה הקבוצה.
- ללחוץ למטה CREATE.
לחזור על התהליך עבור כל Zone שבו יש לנו מכונות באשכול.
המטרה הראשונית היא שתהיה לפחות מכונה אחת ב-Zone a ואחת ב-b. משם אפשר להוסיף ל-c ואז עוד מכונות שמתפזרות ב-Zone השונים. אבל לפחות שתי מכונות, מפוצלות לשני Zone.
לפני שנוכל להקים LB, צריך להקים Instance Groups שה-LB יוכל להפנות אליהן תעבורה.
כל Instance Group חי בתוך גבולות Zone. לכן כל קבוצה כזו רואה רק שרתים שנמצאים ב-Zone שבו נוצרה.
- בתפריט שלושת הפסים, ללכת ל-Compute Engine ושם ל-Instance groups.
- ללחוץ למעלה על CREATE INSTANCE GROUP.
- בדף שיפתח, ללחוץ משמאל על New unmanaged instance group.
- לתת שם. כדאי לכלול את האות של ה-Zone בשם.
- לבחור מיקום. במקרה שלנו זה אזור תל אביב, ואז Zone a ובקבוצה הבאה Zone b.
- לבחור את הרשת שבה חיה הקבוצה.
- ללחוץ למטה CREATE.
לחזור על התהליך עבור כל Zone שבו יש לנו מכונות באשכול.
המטרה הראשונית היא שתהיה לפחות מכונה אחת ב-Zone a ואחת ב-b. משם אפשר להוסיף ל-c ואז עוד מכונות שמתפזרות ב-Zone השונים. אבל לפחות שתי מכונות, מפוצלות לשני Zone.
הקמת Healthcheck:
כדי ש-Load Balancer ידע לשלוח תעבורה רק לשרת תקין שיכול לספק את השירות, כל LB שולח Health Check לשרתים שמאחוריו. השליחה מתבצעת במחזוריות קבועה, ולפי התגובה LB יודע אם הוא יכול להפנות לשם בקשות שירות.
- עדיין תחת Compute Engine, ללכת ל-Health checks.
- ללחוץ CREATE HEALTH CHECK.
- לתת שם – נגיד: sql-48999.
- לבחור אם הבדיקה חיה רק ב-Region או שהיא גלובאלית. בדיקה שהיא Regional לא תעבוד עם Global LB. אבל במקרה שלנו נבחר Regional.
- הבדיקה שלנו מתבצעת בשליחת בקשה פשוטה (כמו Telnet) בפורט מסוים. אז נבחר פורט 48999.
- בשדה של check interval למטה, אפשר לבחור באיזו תדירות נשלחת הבדיקה.
- בשדה של Timeout קובעים כמה זמן ה-LB ממתין לקבלת תשובה (במקרה ואין תשובה), עד שהוא קובע שהבקשה נכשלה.
- בשדות של Healthy/Unhealthy threshold, קובעים כמה פעימות רצופות של תשובה מסוימת, מגדירות שינוי סטטוס. למשל, כמה בדיקות צריכות להכשל ברצף, כדי שה-LB יקבע שהכתובת הזו אינה תקינה ולא להפנות אליה בקשות.
באותה המידה מגדירים כמה בדיקות צריכות לחזור תקינות, כדי לקבוע שהכתובת חזרה לתקינות. - ללחוץ CREATE.
הקמת Load Balancer:
בתפריט GCP (שלושת הפסים למעלה משמאל):
- Network Services >> Load Balancing
- ללחוץ על + CREATE LOAD BALANCER
- לבחור Network Load Balancer, ללחוץ NEXT.
- לבחור Passthrough load balancer, ללחוץ NEXT.
- לבחור Internal, ללחוץ NEXT.
- ללחוץ על CONFIGURE.
- לתת שם, לבחור Region (תל אביב כמובן), לבחור רשת שבה נציב את ה-LB.
- בהגדרות backend, להוסיף כל instance Group שיצרנו בתור backend נפרד.
- לבחור את ה-healthcheck עבור SQL.
- בהגדרות Frontend, לתת שם ל-Forwarding Rule.
- לבחור ב-Subnet שבו יושבת הכתובת שהוגדרה ל-Availability Group.
- לבחור סוג כתובת Ephemeral custom, ולשים שם את הכתובת של ה-Availability Group.
- לסמן שהכתובת הזו משמשת את כל הפורטים.
- לשמור וליצור את ה-LB.
כעת ניתן להכנס לדף של ה-LB ולראות שה-Instance Group שמכיל את השרת שכרגע בתפקיד הראשי, נמצא בירוק והשני עם סימון משולש צהוב.
אם כן, הכל תקין. ניתן להקפיץ את תפקיד השרת הראשי לשרת האחר, ולראות שגם הסימון הירוק עובר איתו ל-Instance Group האחר.
והנה יש לנו Availability Group בסביבת GCP.