ניצול טוקנים מיטבי מול Claude Code
ניתן לעבד 8.83 מיליארד טוקנים בחודש על מנוי Claude, בלי להיתקל במגבלת חלון השעות
הייתי בכנס על עבודה עם Claude דרך GCP. שמעתי שוב ושוב, גם מהדוברים וגם מעמיתים, את אותה תלונה: כולם מגיעים למגבלת השימוש בתדירות גבוהה, ורבים מהם משלמים על המנוי הכי יקר, Max 20x (200$ לחודש).
אני בונה ומתחזק שתי מערכות שלמות במקביל, על מנוי של Max 5x (100$ לחודש), ובקושי נתקל במגבלה. תמיד הנחתי שאני משתמש כבד, אבל התלונות בכנס ערערו לי את ההנחה: אם כולם נחסמים (גם על מנוי יקר יותר) ורק אני לא: אולי אני משתמש קל יחסית?
אז ישבתי ובדקתי את הנתונים, והתברר שההיפך הוא הנכון.
גילוי נאות: נתוני הטוקנים והמודלים חולצו מקובצי ה-transcript המקומיים של Claude Code. נתוני התפוקה, כמו קומיטים, שורות ונכסים, נמדדו מהיסטוריית git וממערכת-הקבצים.
רובד 1: ההספק שאובחן
חודש עבודה אחד מסתכם בנפח שמזכיר יותר מערכת אוטומטית או צוות שלם, מאשר מפתח יחיד מול מקלדת:
| מדד | ערך |
|---|---|
| סה”כ טוקנים שעובדו | 8.83 מיליארד |
| מתוכם, הוגשו מהמטמון | 95.7% |
| מנוף המטמון | ×6.7 |
| המנוי | Claude Max 5x (100$ לחודש) |
| פגיעות במגבלה החודש | מקרה בודד (ניסוי מול Fable, מודל יקר ובזבזן כפליים מ-Opus) |
8.83 מיליארד הם סך הטוקנים שעובדו, אבל הרוב המוחלט שלהם הגיע מהמטמון, מוכן, בלי שעובד מחדש. במונחי עיבוד-בפועל זה שקול ל-1.31 מיליארד טוקנים טריים בלבד (טוקנים שעוברים עיבוד מלא, לא מהמטמון), מנוף של פי-6.7. על המנגנון נרחיב בהמשך.
ההספק הזה הוא תוצאה של עבודה רבה בעצימות גבוהה ובערוצים מקבילים:
| מדד | ערך |
|---|---|
| שעות עבודה פעילות בחודש | ~138 |
| קצב ממוצע לשעת-עבודה | 64 מיליון טוקנים |
| שעת השיא | 196 מיליון |
| חלון 5 השעות העמוס ביותר | 496 מיליון |
| שיחות במקביל (שגרה) | 2 עד 3 |
| שיא שיחות בו-זמנית | 5 |
הבהרה על המקבילות: ל-Anthropic יש נתון רשמי, שמתפרסם במסמכי Claude Code. ממוצע צריכה ארגוני של כ-13$ למפתח ביום-עבודה פעיל, ו-150 עד 250$ למפתח בחודש. 90% מהמשתמשים נשארים מתחת ל-30$ ליום פעיל. בהמרה גסה לטוקנים (ההמרה שלי, כי הנתון הרשמי נקוב בדולרים) זה כ-300 עד 600 מיליון טוקנים בחודש. זו נקודת-ייחוס חזקה ואמינה. מה שאנתרופיק לא מפרסמת הוא צריכה ממוצעת רשמית פר-תוכנית (Max 5x מול 20x); שם ההשוואה נשענת על דיווחים פומביים בטווחים רחבים. גם מולם, לא נראה שמדובר בשימוש קל:
| נקודת ייחוס | טוקנים בחודש | היחס כאן |
|---|---|---|
| מפתח ארגוני טיפוסי (נתון Anthropic רשמי) | 300 עד 600 מיליון | פי 15 עד 30 |
| משתמש Max 20x כבד (ניסוי 30 יום) | 1.2 עד 1.5 מיליארד | פי 6 עד 7 |
| המשתמש הקיצוני המתועד (Opus) | 4.5 עד 6 מיליארד | פי 1.5 עד 2 |
זהו שימוש בקצה העליון של מה שמתועד פומבית. מעל המשתמש הכבד ביותר שנמצא, שחורג מהמגבלה כל הזמן על תוכנית גדולה יותר. ובכל זאת, אצלי אין כמעט התנגשות במגבלה. נראה שלא רק כמות העבודה קובעת, אלא באילו דרכים היא מתבצעת. לכך מוקדש הרובד הבא.
רובד 2: המנגנון, ולמה הוא לא נחסם
הפער הזה אפשרי בזכות כמה מנופים שעובדים יחד. בקצרה, ועם הנתונים שמוכיחים שכל אחד מהם הופעל בפועל:
מטמון (caching). 95.7% מהקלט הוגש מהמטמון. כדי להבין למה זה קריטי, צריך לדעת איך עובדת שיחה מול המודל: בכל בקשה נשלחת מחדש כל היסטוריית-ההקשר המצטברת. כלומר הוראות-המערכת, הגדרות-הכלים, וכל תורות-השיחה הקודמות. עיבוד מחדש של כל ההיסטוריה הזו בכל סבב הוא החלק היקר. המטמון פותר בדיוק את זה: ההקשר ששמור בו אינו מעובד מאפס בכל פעם, אלא מוגש מוכן, וזול בהרבה. רק התוספת החדשה, ההודעה האחרונה, עוברת עיבוד מלא. לכן 8.83 מיליארד שעובדו מתכווצים לשווה-ערך של 1.31 מיליארד טריים. וזה אינו טריק תמחור, אלא מנגנון רשמי של Anthropic.

ניתוב מודלים דיפרנציאלי. לא כל משימה דורשת את המודל היקר. 54.6% מהמשימות כבר רצות מחוץ ל-Opus. המודל הקטן והזול ביותר, Haiku, ביצע לבדו 6,757 סריקות מכניות, כלומר העבודה הזולה והמשעממת נדחפה החוצה מהמודל החזק.
סוכני-משנה שמחזירים פלט מזוקק. 714 הפעלות תת-סוכן עיבדו 1.2 מיליארד טוקני קלט, והחזירו לשיחה הראשית 0.4% בלבד. וכאן החיסכון הגדול הוא דווקא בקלט, לא בפלט: העבודה הכבדה (קריאת קבצים, חיפושים, מבואות סתומים) מתבצעת בהקשר של סוכן-המשנה, ולא נכנסת לשיחה הראשית. לכן השיחה הראשית נשארת רזה, וזכרו שאת היסטוריית-ההקשר שלה משלמים מחדש בכל סבב. סוכן-המשנה מחזיר רק תקציר מזוקק, אז ההקשר הראשי לא תופח, לא חוזר ומעובד שוב ושוב, וגם לא מגיע להצפה שכופה כיווץ ואובדן-מידע.
הוכחה מחלון אמיתי. הצילום הבא הוא של חלון 5 שעות בהספק גבוה, רגעים לפני שהתאפס:
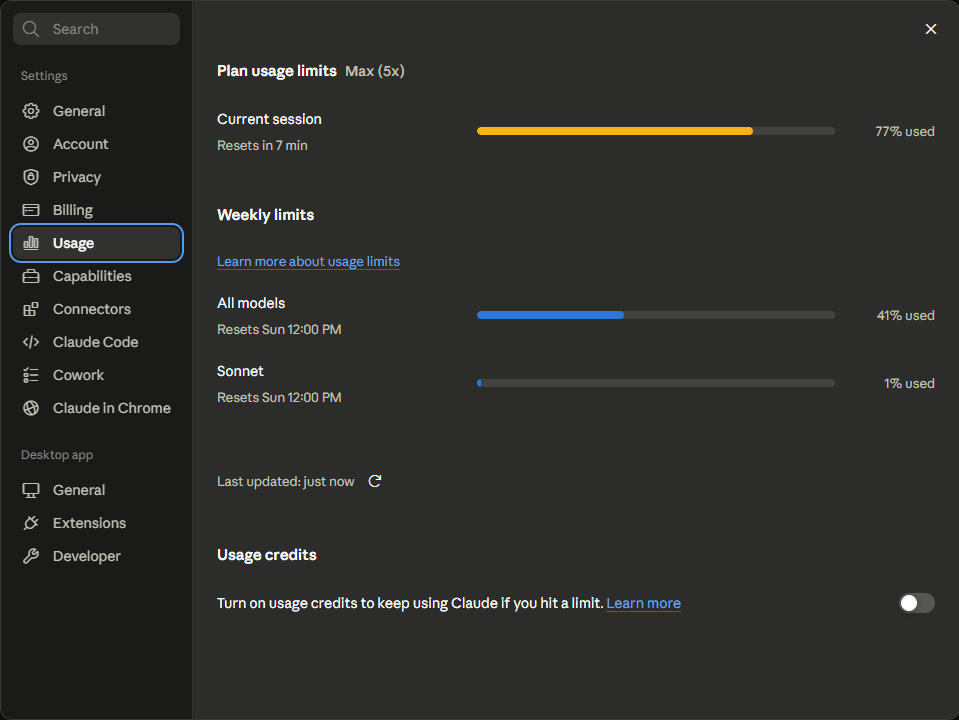
זה לא היה חלון רגוע. בתוכו עובדו מעל 300 מיליון טוקנים. 96.7% מהם מהמטמון, עם שתי שעות שכל אחת חרגה מעל 100 מיליון. וכאן נקודה שיכולה להטעות: שתי השעות הכבדות האלה התאפיינו בהרצת מודלים מקומיים, סקריפטים ובדיקות.
ואם כל אלה רצים מחוץ ל-Claude, למה דווקא שעות אלה הן הכבדות בטוקנים? התשובה: אמנם ייצור-התוכן עצמו אכן רץ על המחשב המקומי באפס טוקנים. אבל כדי לתזמר עשרות ריצות-מודל וסקריפטים בשעה, Claude Code מבצע הרבה סבבי-פקודה-וניטור. כל סבב נושא איתו את ההקשר-החם מהמטמון. כלומר, המספר הגבוה הוא בעיקר קריאות-מטמון זולות מהאורקסטרציה הצפופה, לא עיבוד יקר.
וזו דווקא הוכחה מחזקת: אפילו השעות שנראות “יקרות” הן ברובן מטמון-זול ועבודה שרצה מחוץ למחזור-הטוקנים.
ובכל זאת, המונה הראה 77% בלבד, עם 7 דקות עד האיפוס. גם תחת ההספק הגבוה המתועד כאן, נשמר מרחק בטוח מהמגבלה.
הערת-אגב על המספר: באותו ערב, במדידה מאוחרת יותר עם סגירת חלון-השעות, המצטבר החודשי כבר חצה את 9 מיליארד טוקנים. המספר הזה לא עבר ניתוח-הרכב מלא כמו 8.83 המיליארד, ולכן הוא נשאר כאזכור בלבד ולא נכנס לסטטיסטיקות הראשיות. העוגן הקנוני בכל המאמר הוא 8.83 מיליארד, השמרני והמנותח.
בבדיקה של כל החודש מצאתי פגיעה אחת במגבלת חלון 5 השעות. ביום שבו ניסיתי את המודל החדש Fable - שיקר ובזבזן כפליים מ-Opus. מעבר למקרה הבודד הזה, לא נחסמתי. ההיתקלות במגבלה הזו אצלי נדירה מאוד, פעמים בודדות בחצי שנה.
המקרה הבולט היה כש-Anthropic שינתה את מודל התמחור וקיצצה את חלון-הטוקנים לסשן ואת אורכו. התאמה מהירה של חוקי-העבודה של צוות-הסוכנים החזירה את הזרימה לרציפות. גם זו עדות לכך שהפתרון ארכיטקטוני, ומסתגל כשהכללים משתנים.
רובד 3: זה לא טוקנים שמתאדים, זו תפוקה
נפח טוקנים יכול להיות רעש. אז מה באמת נבנה באותו חודש? המספרים הבאים נמדדו משני מקורות בלתי-תלויים: היסטוריית git של מערכת הלוגיסטיקה, מדויקת ברמת-הקומיט, ומערכת-הקבצים של פרויקט המשחק שבפיתוח (שאינו תחת git).
| תוצר | כמות |
|---|---|
| קומיטים | 86 |
| שורות קוד שנכתבו | ~65,000 |
| קבצים: שונו · נוצרו | 680 · 433 |
| פריסות (רובן לכל הסביבות, כולל ייצור) | 14 |
| קובצי בדיקה חדשים | 40 |
| מסמכי תכנון ותיעוד | מעל 90 |
| נכסי-אמנות גרפיים (מודלים מקומיים) | ~970 |
| ריצות ייצור-תמונה מקומיות | 1,242 |
מילה על מה שהמספרים אומרים, ולא אומרים. רוב 65 אלף השורות הן מיגרציה: שכתוב השירות המרכזי של ה-backend - השירות המרכזי והגדול ביותר של המערכת. משפת Node.js לשפת Rust. תהליך שאומת בקפדנות ב-165 מתוך 165 תרחישי-תאימות מול המקור, ולא תרגום שורה-בשורה אלא מימוש-מחדש בשפה עם תפיסת-עולם שונה לחלוטין (טיפוסים סטטיים במקום דינמיים, ניהול-זיכרון בבעלות מפורשת, ומודל מקביליות אחר).
שורות-קוד הוא מדד גרוע לתפוקה, ולכן הסיפור אינו רק הכמות אלא המגוון: באותו חודש, אותו אדם, אותו מחשב, יצאו backend משוכתב ומאומת, זרם-תכונות במערכת חיה, ומנוע-משחק שני עם ~970 נכסי-אמנות והצינור שמייצר אותם. זו טביעת-רגל של צוות קטן, לא של מפתח-יחיד.
תפוקה ומגוון כאלה פשוט אינם ניתנים להשגה בחזרתיות. אחוז-המטמון הגבוה אינו לעיסת-אותו-דבר, אלא ארכיטקטורה שמאפשרת לרוץ על הקשר חם תוך כדי שמייצרים דברים שונים מאוד זה מזה.
רובד 4: לא רק יותר, אלא טוב ואיכותי יותר
נניח שהשתכנעת שלא חזרתי על עצמי, ושבאמת נוצרה כמות אדירה של קוד ונכסים. נשארת שאלת האיכות: אולי הרבה מהכמות הזו הוא פשוט זבל?
אז מדדתי איכות מול נתוני-תעשייה פומביים, מסונן לקוד שנגעתי בו החודש בלבד:
| מדד | אצלי | בנצ’מרק תעשייתי |
|---|---|---|
| כתיבה-חוזרת של קוד (churn) | 2.32% (קוד-מוצר) | 7.1% בתעשייה היום, 3.3% אצל אדם לפני עידן ה-AI |
| רעש-טוקן (בזבוז) | ~10-30% | 40-80% |
| באגים חדשים שנכנסו לקוד החודש | אפס שגיאות-לוגיקה חדשות | (השגיאות הקיימות הן חוב ישן) |

קוד-מוצר שנכתב-מחדש בשיעור נמוך מהאדם הממוצע לפני עידן-ה-AI, ורעש-טוקן כחצי מהמקובל. אפילו הגירת-Rust האיטרטיבית (5.01% churn) יושבת מתחת לנורמת-ה-AI. שני אותות-איכות בלתי-תלויים מצביעים לאותו כיוון: ניתוח-סטטי (eslint+clippy) על קוד-החודש מצא אפס שגיאות-לוגיקה חדשות, רק אזהרות-סגנון, בעוד שכל שגיאות-הלוגיקה הקיימות הן חוב בן-שנים שלא נגעתי בו. ושיטה שנייה, ניתוח git-blame שבודק כמה מהשורות שנכתבו החודש תוקנו אחר-כך, מצאה שיעור-באגים של ~2.1% בקוד החדש, עקבי עם ה-churn.
ולמה הקוד יצא גם מהר וגם נקי? כאן נמצאת הנקודה הכי חשובה במאמר. זה לא קרה במקרה, אלא בגלל סדר-עבודה: מודול או מיגרציה גדולים מתוכננים קודם, ביסודיות, בקבצי-תכנון. הגירת ה-Rust, למשל, נשענה על שלד-תכנון מדוד של ~17,800 שורות ו-~190 אלף מילים, פלוס 165 תרחישי-תאימות, עוד לפני שורת-קוד אחת של מימוש.
המנגנון פשוט: כל המחשבה הקשה נעשית פעם אחת, מראש, מול תוכנית שלמה, במקום להמציא תוך-כדי-כתיבה. ואז שלב הביצוע רץ גם זול וגם מדויק. זול, כי קבצי-התכנון כבר יושבים במטמון, ולכן הביצוע מולם כמעט לא מעבד שום דבר מחדש (במדידה: שיחות-התכנון רצו ב-84% מטמון, ושיחות-הביצוע מולן ב-97%). ומדויק, כי הכיוון כבר הוכרע ובדוק, אז יש פחות כתיבה-חוזרת. סיבה אחת, שתי תוצאות: עלות נמוכה יותר ואיכות גבוהה יותר.
לסיום, לשם ההגינות: מדד-איכות אחד לא בדקתי. לא השוויתי את שיעור-הבאגים שלי לשיעור-הבאגים של מתכנת אנושי על אותה משימה בדיוק, פשוט כי אין לי מדידה כזו. אז הטענה היא על כל מדד שכן נמדד, לא על כל מדד אפשרי. אבל בכל מדד שנמדד, הכיוון אחד.
רובד 5: כמה זה שווה
רק עכשיו, אחרי שהונחו ההספק, התפוקה והאיכות, אפשר לתרגם לכסף בלי שזה יישמע כמו הפרחת-מספרים. אם אותו עיבוד-טוקנים היה רץ מול ה-API, במחירון הרשמי:
| תרחיש | עלות (שווה-ערך API) |
|---|---|
| מודלים אמיתיים + מטמון (מה שקרה בפועל) | ~$18,200 |
| רק Opus + מטמון | ~$24,200 |
| מודלים אמיתיים, בלי מטמון | ~$106,000 |
| רק Opus, בלי מטמון | ~$136,000 |

מה שמפריד בין הרצפה (18,200 דולר) לתקרה (136,000) הוא בדיוק שני המנופים: מטמון גבוה וניתוב-מודלים. העיבוד בפועל הוא 13.4% מהתרחיש-הגרוע.
וצריך לדייק: אפילו ה-18,200 אינו קו-בסיס נייטרלי. הוא כבר מגלם 95.7% מטמון וניתוב-מודלים. משתמש שאין לו אותם, על אותה עבודה, לא נוחת על 18,200 אלא נודד מעלה אל תרחישי שש-הספרות. ועל ציר-המגבלה זה חמור אף יותר: בלי המטמון אותו נפח דורש פי-6.7 טוקנים טריים, שמפוצצים את תקרת חלון-5-השעות פי-כמה, כך שמשתמש כזה לא רק משלם הרבה יותר, אלא נחסם כמעט מיד. ההספק הגבוה במנוי של 100$ אינו מתנה מ-Anthropic, אלא פרס על ארכיטקטורת-עבודה.
וחשוב לזכור מה הסכומים האלה מודדים: רק את שווי-ה-API של עיבוד-הטוקנים. הם אינם כוללים את כל העבודה שהתבצעה מחוץ למחזור-הטוקנים (כפי שיתואר ברובד הבא), למשל ייצור ~970 הנכסים על מודלים מקומיים. לו אותו ייצור היה רץ דרך מודל-ענן עתיר-פלט, הוא היה מפוצץ את המגבלה מיד; כאן הוא צרך אפס. כך ש-136,000 הוא רצפה לשווי-העבודה הכולל, לא תקרה.
רובד 6: השיטה, כעקרונות שאפשר לאמץ
מה שמאפשר לעבוד מבלי להגיע למגבלה זה לא היקף-עבודה נמוך יותר, אלא ארכיטקטורת-עבודה יעילה יותר. כל שכבה מורידה את העלות האמיתית של כל סבב בלי להוריד את כמות העבודה, ורובן ניתנות לאימוץ על ידי כל משתמש Claude:
-
צוות-סוכנים מותאם שמריץ את עצמו. במקום שיחה אחת שתופחת, צוות-סוכנים מותאם לפרויקט ולדרך-העבודה, שיודע לקחת כל משימה אל הסוכן המתאים ולהאציל בעצמו לסוכני-משנה. העבודה הכבדה (קריאות, חיפושים, סריקות) נשארת מחוץ לשיחה המרכזית ולא מזהמת את ההקשר שלה.
-
ניתוב מודלים לפי קושי המשימה. התאמה שיטתית של המודל לקושי מורידה דרמטית את העלות, בלי לפגוע באיכות במקומות שדורשים אותה. Opus שמור למה שבאמת צריך אותו, Haiku ו-Sonnet לשאר.
-
כלים שמריצים עבודה מחוץ למחזור-הטוקנים. סקריפט, test harness או פייפליין שנבנים פעם אחת ומופעלים שוב ושוב. הכלי מבצע את עבודת-האצווה בעצמו, והעלות מצטמצמת לטוקנים של מתן-הפקודה וניטור-התוצאה בלבד. 47% מפקודות ה-shell בחודש היו הפעלת מנגנונים כאלה.
-
האצלת ייצור למודלים מקומיים, ש-Claude Code מתזמר. עבודה יצרנית כבדה, כמו יצירת נכסים גרפיים, רצה על מודלים מקומיים על החומרה שלך, מחוץ ל-Claude לגמרי, באפס טוקנים. ל-Claude Code נשאר תפקיד המנצח: הוא כותב את תהליכי-העבודה, מפעיל אותם, ומנהל את כל הצינור כתהליך אחד. ומעבר לחיסכון, זה נותן בעלות מלאה ונקייה על התוצר, וארגז-כלים רב-מודאלי שאפשר להעשיר ולהחליף ככל שהשדה זז.
-
תכנון ב-Markdown ואז ביצוע. כפי שראינו ברובד 4: המאמץ היקר מושקע פעם אחת בקבצי-תכנון, ואז הביצוע רץ מולם זול ומדויק. ואפשר אפילו לכתוב את קבצי-התכנון עצמם עם Claude Code, אבל יחד עם המשתמש ולפי הוראותיו המדויקות, כך שהתוצאה היא תוכנית שאתה עומד מאחוריה, לא כזו שנכפתה עליך.
-
מטמון והחלפת-שיחות במידה הנכונה. עבודה רציפה משאירה את המטמון חם. הכלל הפשוט: להמשיך באותו נושא עד שההקשר מתמלא ואז לעבור, אבל לא להישאר בשיחה אחת שדנים בה בעשרה נושאים שונים.
המכנה-המשותף: Claude Code אינו רק מבצע עבודה, אלא מנהל אותה. הוא מאציל לסוכני-משנה ולכלים חיצוניים, בודק את מה שחזר, שולח למקצה-שיפורים, ומוודא שמתקבל תוצר מוגמר באיכות טובה. הוא המרכז שמתזמר עבודה שחלקה הגדול רץ מחוצה לו.
סיכום
המגבלה שכולם נתקלים בה אמיתית, אבל היא אינה גזירת-גורל ולא חסם בל-יעבור. יש לנו השפעה עצומה על המקום שבו ניתקל בה, אם בכלל. כשרוב הקלט מוטמן, כשהעבודה הכבדה יושבת בסוכני-משנה ובכלים חיצוניים, וכשהמודל היקר שמור רק למה שבאמת דורש אותו, אפשר לעבד נפח עצום על המנוי הזול ועדיין לצאת עם תפוקה רחבה ואיכותית.
כל אחת מהשכבות האלה היא עיקרון שאפשר לאמץ. ההבדל בין מי שפוגש את הקיר למי שלא: לא התוכנית שמשלמים עליה, אלא איך בונים את זרימת-העבודה.
זו לא שאלה של כמה. זו שאלה של ארכיטקטורה.
מתודולוגיה ומקורות
נתוני השימוש (פרט להשוואות) חולצו מקובצי ה-transcript המקומיים של Claude Code, המתעדים לכל הודעה את פירוק-הטוקנים ואת קריאות-הכלים. התקופה: 26/05 עד 25/06/2026 (~31 ימים; Claude Code מוחק transcripts ישנים, ולכן זהו חודש מייצג). נתוני התפוקה (קומיטים, שורות, קבצים) נמדדו ישירות מהיסטוריית git. הסכומים בדולרים הם שווה-ערך במחירון API הרשמי, לא חיוב בפועל (שולם מנוי קבוע). ספירות-הכלים הן הערכה (התאמת מילות-מפתח), לא ספירה מדויקת.
ההשוואות מול משתמשים אחרים: ל-Anthropic יש נתון רשמי, ממוצע צריכה ארגוני (כ-13$ ליום ו-150 עד 250$ לחודש למפתח, 90% מתחת ל-30$ ליום; ראו הקישור הראשון למטה), וזו נקודת-ייחוס אמינה. צריכה ממוצעת פר-תוכנית (Max 5x מול 20x) אינה מתפרסמת רשמית, ולכן ההשוואות פר-תוכנית נשענות על דיווחים פומביים בטווחים רחבים. מכפילי-התוכניות (Max 5x = פי-5 מ-Pro, Max 20x = פי-20) רשמיים.